CSVファイルの圧力分布をもとにpythonを使ってCalculiXで分布荷重を設定する
はじめに
pythonを使ってCSVファイルをもとにCalculiXで分布荷重を設定する
今回は、航空機の主翼の表面にはたらく圧力分布をXFRL5という別ソフトで計算してCSVとして保存している前提で、そのCSVファイルをCalculiXの書式に合わせて書き換えるプログラムを作成した
↓公式ドキュメント

↓参考
https://www.bconverged.com/content/calculix/doc/GettingStarted.pdf
↓ベースになる.inpファイル

↓ベースになる.csvファイル
https://github.com/mtkbirdman/mtkbirdman.com/blob/master/OpenVSP/FEA/Cp.csvそれではいってみよう
Calculixにおける荷重設定
CalculiXにおける荷重設定は、一般的に以下の流れで構成される
*STEP
*STATIC
*CLOAD
1, 3, -1000.0
*DLOAD
Shell, GRAV, 9.81, 0, 0, -1
*EL FILE,
S, E
*NODE FILE
U
*END STEP*STEP:新しい解析ステップの開始する*STATIC:静的解析を行う。
静的解析では、時間の影響を無視して荷重が適用され、構造の応答が計算される*CLOAD:節点に集中荷重を適用する1, 3, -1000.0:節点1にZ方向に-1000.0の荷重が適用される
節点番号、荷重の方向、荷重として入力する(荷重の方向は1:X方向、2:Y方向、3:Z方向)*DLOAD:要素に分布荷重を適用するShell, GRAV, 9.81, 0, 0, -1:Shellという要素セットのすべての要素に、下向き(Z軸の負の方向)の重力荷重を適用する*EL FILE,:要素の出力を指定するS, E:各増分で応力SとひずみEを出力する*NODE FILE:節点の出力を指定するU:各増分で変位Uを出力する*END STEP:解析ステップの終了する
↓参考
*CLOAD (mit.edu)
*DLOAD (mit.edu)
Static analysis (mit.edu)
*NODE FILE (mit.edu)
*EL FILE (mit.edu)
ソースコード
ソースコードはこれ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.interpolate import griddata
class AirfoilProcessor:
def __init__(self, file_path):
# 引数:
# file_path (str): 入力ファイルのパス
self.file_path = file_path # 入力ファイルのパスをインスタンス変数に格納
# インスタンス変数の初期化
self.nodes = None # 節点データを格納するための変数を初期化
self.elements = None # 要素データを格納するための変数を初期化
self.average_coordinates = None # 平均座標データを格納するための変数を初期化
# 節点データと要素データの読み込みメソッドを呼び出し
self.read_node() # 節点データを読み込むメソッドを呼び出し
self.read_element() # 要素データを読み込むメソッドを呼び出し
def read_node(self):
# 節点データを読み込み、DataFrameに変換するメソッド
data = [] # 節点データを格納するリストを初期化
# 入力ファイルを読み込む
with open(self.file_path, 'r') as file:
lines = file.readlines() # ファイルの全行を読み込み、リストに格納
node_data = [] # 一時的に節点データを格納するリストを初期化
reading_node = False # 節点データ読み込みフラグを初期化
NSET = None # 現在のNSETの値を格納する変数を初期化
# ファイルの各行を処理
for line in lines:
line = line.strip() # 行の前後の空白を削除
# 節点セクションの開始を検出
if line.startswith('*NODE'):
reading_node = True # 節点データ読み込みフラグをセット
NSET = line.split('=')[1] # NSETの値を取得
# 節点データを読み込んでいる間の処理
elif reading_node and line:
# 行のデータを分解してリストに変換
line_data = [int(line.split(',')[0])] + [float(x) for x in line.split(',')[1:]]
line_data.append(NSET) # NSETの値を追加
node_data.append(line_data) # 分解したデータを一時リストに追加
# 空行を検出し、節点データセクションの終了を処理
elif reading_node and not line:
if node_data:
data.extend(node_data) # 一時リストのデータをメインリストに追加
node_data = [] # 一時リストをクリア
reading_node = False # 節点データ読み込みフラグをリセット
# 節点データをDataFrameに変換
self.nodes = pd.DataFrame(data, columns=['NODE', 'X', 'Y', 'Z', 'NSET'])
self.nodes.set_index('NODE', inplace=True) # 'NODE'列をインデックスに設定
def read_element(self):
# 要素データを読み込み、DataFrameに変換するメソッド
data = [] # 要素データを格納するリストを初期化
# 入力ファイルを読み込む
with open(self.file_path, 'r') as file:
lines = file.readlines() # ファイルの全行を読み込み、リストに格納
element_data = [] # 一時的に要素データを格納するリストを初期化
reading_element = False # 要素データ読み込みフラグを初期化
ELSET = None # 現在のELSETの値を格納する変数を初期化
# ファイルの各行を処理
for line in lines:
line = line.strip() # 行の前後の空白を削除
# 要素セクションの開始を検出
if line.startswith('*ELEMENT'):
ELSET = line.split('=')[2] # ELSETの値を取得
reading_element = True # 要素データ読み込みフラグをセット
# 要素データを読み込んでいる間の処理
elif reading_element and line:
# 行のデータを分解してリストに変換
line_data = list(map(int, line.split(',')))
line_data.append(ELSET) # ELSETの値を追加
element_data.append(line_data) # 分解したデータを一時リストに追加
# 空行を検出し、要素データセクションの終了を処理
elif reading_element and not line:
if element_data:
data.extend(element_data) # 一時リストのデータをメインリストに追加
element_data = [] # 一時リストをクリア
reading_element = False # 要素データ読み込みフラグをリセット
# 要素データをDataFrameに変換
self.elements = pd.DataFrame(data, columns=['ELEMENT', 'NODE1', 'NODE2', 'NODE3', 'NODE4', 'NODE5', 'NODE6', 'ELSET'])
self.elements.set_index('ELEMENT', inplace=True) # 'ELEMENT'列をインデックスに設定
def calculate_average_coordinates(self):
# 要素の平均座標を計算するメソッド
average_coordinates = [] # 平均座標を格納するリストを初期化
# 各要素のインデックスと行を取得してループ処理
for index, row in self.elements.iterrows():
# 要素の節点インデックスを取得(最初の値を除く)
element_indices = row.values[1:]
# 節点インデックスに基づいて節点座標を取得
element_coordinates = self.nodes.loc[self.nodes.index.isin(element_indices)][['X', 'Y', 'Z']]
# 節点座標の平均を計算し、リストに変換
average_coordinate = element_coordinates.mean().tolist()
# 平均座標をリストに追加
average_coordinates.append(average_coordinate)
# 平均座標をDataFrameに変換
self.average_coordinates = pd.DataFrame(average_coordinates, columns=['X_avg', 'Y_avg', 'Z_avg'], index=self.elements.index)
# 要素のDataFrameに平均座標を追加
self.elements = pd.concat([self.elements, self.average_coordinates], axis=1)
def set_pressure_distribution(self, cp_file, density=1.225, velocity=10):
# 圧力係数のファイルを読み込みデータフレームに変換
df_Cp = pd.read_csv(cp_file)
# 列のデータ型を数値型に変換し、FutureWarning を避ける
for column in df_Cp.columns:
try:
df_Cp[column] = pd.to_numeric(df_Cp[column])
except ValueError:
pass # 値を数値に変換できなかった場合はそのままにする
# 'Skin', 'Spar_Upper', 'Spar_Lower' を含むELSETの要素を選択し、コピーを作成
df_skin = self.elements.loc[
self.elements['ELSET'].str.contains('Skin') |
self.elements['ELSET'].str.contains('Spar_Upper') |
self.elements['ELSET'].str.contains('Spar_Lower')
].copy()
# 'Surface' 列を 'P' で埋める
df_skin['Surface'] = 'P'
# 要素の平均座標に基づいて翼表面の圧力係数を内挿し、逆符号で 'Cpv' 列を作成
df_skin['Cpv'] = -griddata(df_Cp[['x', 'y']].values, df_Cp['Cpv'].values, df_skin[['X_avg', 'Z_avg']].values, method='nearest')
# 'Cpv' に動圧 (0.5 * 密度 * 速度^2) をかけて圧力を計算し、小数点以下8桁に丸める
df_skin['Cpv'] = round(df_skin['Cpv'] * 0.5 * density * velocity ** 2, 8)
# 'Surface' と 'Cpv' の列のみを 'DLOAD.csv' ファイルに保存(indexが要素番号に対応)
df_skin[['Surface', 'Cpv']].to_csv('DLOAD.csv')
def set_node_loads(self, cp_file, output_file='CLOAD2.csv', density=1.225, velocity=10):
# 圧力係数のCSVファイルを読み込む
df_Cp = pd.read_csv(cp_file)
# 圧力係数データの各列を数値型に変換する
for column in df_Cp.columns:
try:
df_Cp[column] = pd.to_numeric(df_Cp[column])
except ValueError:
pass # 値を数値に変換できなかった場合はそのままにする
# 'RibArray' または 'intersections' を含むNSETの節点を選択し、コピーを作成
df_RibArray = self.nodes.loc[
self.nodes['NSET'].str.contains('RibArray') | self.nodes['NSET'].str.contains('intersections')
].copy()
# 空のリストを作成、後で節点の荷重を格納するためのもの
af_array = []
# 'RibArray' を含むNSETのY値を取得し、ループ処理
for Y in self.nodes.loc[self.nodes['NSET'].str.contains('RibArray')]['Y'].drop_duplicates().tolist():
df_Rib = df_RibArray[df_RibArray['Y'] == Y].copy() # 現在のY値に対応するリブのデータをコピー
af = self.sort_airfoil(df_Rib, x_label='X', y_label='Z') # リブのエアフォイル座標をソート
af_diff = af[['X', 'Y', 'Z']].diff() # エアフォイル座標の差分を計算
af['Label_X'] = 1 # 'Label_X' 列を1で埋める
af['Label_Z'] = 3 # 'Label_Z' 列を3で埋める
af['Cpv'] = griddata(df_Cp[['x', 'y']].values, df_Cp['Cpv'].values, af[['X', 'Z']].values, method='nearest') # 圧力係数の値を内挿し、 'Cpv' 列を作成
af['Pv_X'] = round(-af['Cpv'] * 0.5 * density * velocity ** 2 * af_diff['Z'] * 0.2, 8) # X方向の圧力荷重を計算し、 'Pv_X' 列を作成
af['Pv_Z'] = round(af['Cpv'] * 0.5 * density * velocity ** 2 * af_diff['X'] * 0.2, 8) # Z方向の圧力荷重を計算し、 'Pv_Z' 列を作成
af['NODE'] = af['NODE'].astype(int) # 節点番号を整数型に変換
af['Label_X'] = af['Label_X'].astype(int) # 'Label_X' を整数型に変換
af['Label_Z'] = af['Label_Z'].astype(int) # 'Label_Z' を整数型に変換
# 'RibArray' を含むNSETのデータをフィルタリング
af_CLOAD = af[af['NSET'].str.contains('RibArray')]
af_array += af_CLOAD[['NODE', 'Label_X', 'Pv_X']].values.tolist() # X方向の荷重データをリストに追加
af_array += af_CLOAD[['NODE', 'Label_Z', 'Pv_Z']].values.tolist() # Z方向の荷重データをリストに追加
# 節点の荷重データをデータフレームに変換
af_CLOAD = pd.DataFrame(af_array, columns=['NODE', 'LABEL', 'VALUE'])
af_CLOAD['NODE'] = af_CLOAD['NODE'].astype(int) # 'NODE' 列を整数型に変換
af_CLOAD['LABEL'] = af_CLOAD['LABEL'].astype(int) # 'LABEL' 列を整数型に変換
# 節点の荷重データをCSVファイルに保存
af_CLOAD.to_csv(output_file, index=False)
def plot_airfoil(self, y_value=0):
# 'RibArray' または 'intersections' を含むNSETの節点を選択し、コピーを作成
df_RibArray = self.nodes.loc[
self.nodes['NSET'].str.contains('RibArray') | self.nodes['NSET'].str.contains('intersections')
].copy()
# プロットの設定
plt.figure(figsize=(8, 8)) # プロット領域のサイズを設定
plt.plot(df_RibArray['X'], df_RibArray['Z'], linestyle='-') # X vs Z のグラフをプロット
plt.xlim(0, 1) # X軸の範囲を設定
plt.ylim(-0.5, 0.5) # Y軸の範囲を設定
plt.grid(True) # グリッドを表示
plt.title('Graph of x vs z (y=0)') # グラフのタイトルを設定
plt.xlabel('x') # X軸のラベルを設定
plt.ylabel('z') # Y軸のラベルを設定
plt.show() # グラフを表示
def sort_airfoil(self, df, x_label='x', y_label='y'):
# 空のリストを初期化
airfoil = []
# 節点にインデックスを追加
df['NODE'] = df.index
arg0 = 0
# 後縁点を追加
airfoil = df[df[x_label] == df[x_label].max()].values.tolist()
x0 = df[x_label].max()
y0 = df.loc[df[x_label].idxmax(), y_label]
# ループで翼型座標の節点を後縁→上面を通って前縁→下面を通って後縁 に並び替える
for _ in range(len(df)):
# 距離と角度の計算
df['distance'] = ((df[x_label].values - x0) ** 2 + (df[y_label].values - y0) ** 2) ** 0.5
df['arg'] = abs((np.degrees(np.arctan2((df[y_label].values - y0), (df[x_label].values - x0))) - 90 + 360) % 360 - arg0)
df['param'] = df['distance'] + df['arg'] / 180
# パラメータでソート
df = df.sort_values(by=['param'])
# 次の角度の計算
arg0 = (np.degrees(np.arctan2((df.iloc[0][y_label] - y0), (df.iloc[0][x_label] - x0))) - 90 + 360) % 360
x0 = df.iloc[0][x_label]
y0 = df.iloc[0][y_label]
# 角度が90を超えたら終了
if df.iloc[0]['arg'] > 90:
break
# 翼型座標のリストに追加
airfoil.append(df.iloc[0].tolist())
# 使用した節点の削除
df = df.drop(df.index[0])
# データフレームに変換し、不要な列を削除して返す
airfoil = pd.DataFrame(airfoil, columns=df.columns)
airfoil.drop(columns=['distance', 'arg', 'param'], inplace=True)
return airfoil
def find_closest_node(self, x, y, z):
# 節点と指定された座標との距離を計算
distances = np.sqrt((self.nodes['X'] - x) ** 2 + (self.nodes['Y'] - y) ** 2 + (self.nodes['Z'] - z) ** 2)
closest_index = distances.idxmin() # 最も距離が近い節点のインデックスを取得
# 最も距離が近い節点のインデックスを返す
return closest_index
def set_point_loads(self, point_loads, output_file='CLOAD1.csv'):
# 節点荷重のデータを格納するリストを初期化
point_CLOAD = []
# 各節点荷重について処理を行う
for point in point_loads:
# 指定された座標に最も近い節点を検索
node = self.find_closest_node(*point[:3])
# 節点荷重の各成分について節点と値をリストに追加
for load in point[3:]:
point_CLOAD.append([node] + list(load))
# 節点荷重のデータをDataFrameに変換
df_CLOAD = pd.DataFrame(point_CLOAD, columns=['NODE', 'LABEL', 'VALUE'])
# DataFrameをCSVファイルに保存し、インデックスを含めないようにする
df_CLOAD.to_csv(output_file, index=False)
def update_inp(self, new_file='./SAMPLE.inp'):
# 元のファイルからデータを読み込む
with open(self.file_path, 'r') as file:
lines = file.readlines()
# 全要素セット’EALL’を追加
lines.append('*ELSET,ELSET=EALL' + '\n')
counter = 0
for ELSET in self.elements['ELSET'].drop_duplicates().tolist():
lines.append(ELSET + ',')
counter += 1
if counter == 16: # 1行に16個まで
lines.append('\n')
counter = 0
lines.append('\n')
# 空行を追加
lines.append('\n')
# 新しいステップの追加
lines.append('*STEP' + '\n')
lines.append('*STATIC' + '\n')
lines.append('*CLOAD' + '\n')
# CLOAD1.csv ファイルの内容を追加
with open('./CLOAD1.csv', 'r') as file:
lines += file.readlines()[1:]
# CLOAD2.csv ファイルの内容を追加
with open('./CLOAD2.csv', 'r') as file:
lines += file.readlines()[1:]
# DLOAD.csv ファイルの内容を追加
lines.append('*DLOAD' + '\n')
lines.append('EALL,GRAV,9.81,0.,0.,-1.' + '\n')
with open('./DLOAD.csv', 'r') as file:
lines += file.readlines()[1:]
# 出力設定を追加
lines.append('*NODE FILE' + '\n')
lines.append('U' + '\n') # 節点変位を出力
lines.append('*EL FILE' + '\n')
lines.append('S,E' + '\n') # 要素歪みを出力
lines.append('*END STEP' + '\n')
# 新しいファイルとして保存
with open(new_file, 'w', encoding='utf-8') as file:
file.writelines(lines)
if __name__=='__main__':
# 入力ファイルのパスを指定して、AirfoilProcessor オブジェクトを作成する
file_path = 'SAMPLE_WingGeom_Struct0_calculix.inp'
processor = AirfoilProcessor(file_path)
# 節点と要素の平均座標を計算する
processor.calculate_average_coordinates()
# 圧力分布を設定する。密度と速度のパラメータも指定する。
processor.set_pressure_distribution(cp_file='Cp.csv', density=1.164, velocity=9.6)
# 節点への荷重を設定する。密度と速度のパラメータも指定する。
processor.set_node_loads(cp_file='Cp.csv', density=1.164, velocity=9.6)
# 点荷重を設定する。point_loads は各点の座標とその点に作用する荷重のリスト。
point_loads = [
(0.2814, 2.5, -0.023528, (2, 5000)),
(0.2814, 2.5, 0.096550, (1, -100), (2, -5000), (3, 130)),
(0.365, 2.5, -0.019471, (1, 100), (2, 5000)),
(0.365, 2.5, 0.098803, (2, -5000), (3, 130))
]
processor.set_point_loads(point_loads)
# 新しい入力ファイルを更新して保存する
processor.update_inp()
各メソッドの詳しい使い方はソースコードを参照
実際の実行部分はここ
if __name__=='__main__':
# 入力ファイルのパスを指定して、AirfoilProcessor オブジェクトを作成する
file_path = 'SAMPLE_WingGeom_Struct0_calculix.inp'
processor = AirfoilProcessor(file_path)
# 節点と要素の平均座標を計算する
processor.calculate_average_coordinates()
# 圧力分布を設定する。密度と速度のパラメータも指定する。
processor.set_pressure_distribution(cp_file='Cp.csv', density=1.164, velocity=9.6)
# 節点への荷重を設定する。密度と速度のパラメータも指定する。
processor.set_node_loads(cp_file='Cp.csv', density=1.164, velocity=9.6)
# 節点荷重を設定する。point_loads は各点の座標とその点に作用する荷重のリスト。
point_loads = [
(0.2814, 2.5, -0.023528, (2, 5000)),
(0.2814, 2.5, 0.096550, (1, -100), (2, -5000), (3, 130)),
(0.365, 2.5, -0.019471, (1, 100), (2, 5000)),
(0.365, 2.5, 0.098803, (2, -5000), (3, 130))
]
processor.set_point_loads(point_loads)
# 新しい入力ファイルを更新して保存する
processor.update_inp(new_file='./SAMPLE.inp')処理の概要は以下の通り
- .inpファイルを読み込んで、節点座標および要素の中心座標を計算する
- スキンの部分の要素の中心座標に基づいて圧力の分布荷重を設定する
- フィルムの部分にかかる圧力の分布荷重をもとにリブ側面に節点荷重を設定する(フィルムにかかる圧力がリブ側面から伝達されると仮定)
- 外翼から伝達される曲げ、ねじり、剪断力を桁の端に節点荷重として設定する
- 上記をCalculiXの書式にして.invファイルを更新する
使い方
以下のファイルを同じディレクトリに置いた状態で、inp.pyを実行する
- inp.py
- .inpファイル
- Cp.csv
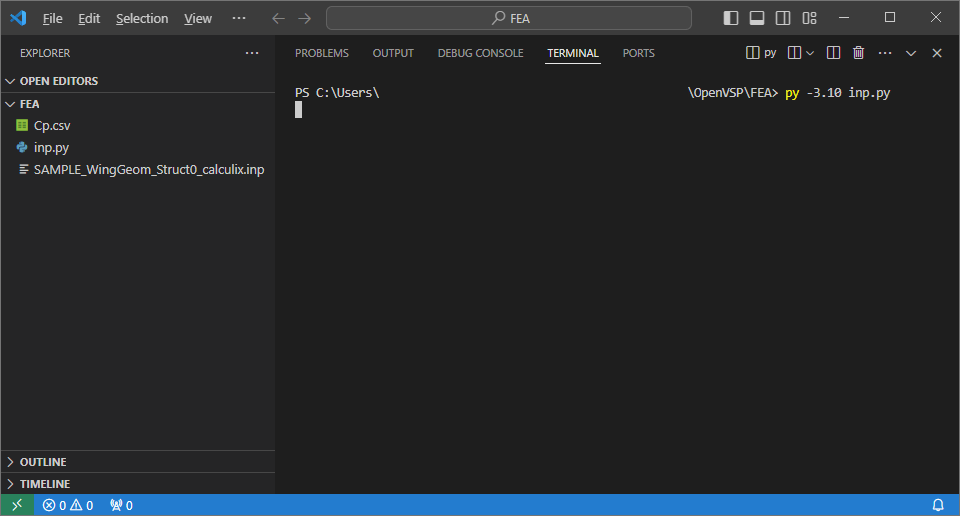
プログラムが完了すると、同じディレクトリにCLOAD1.csv、CLOAD2.csv、DLOAD.csvが出力され、更新された.inpファイルが出力される(今回はSAMPLE.inp)
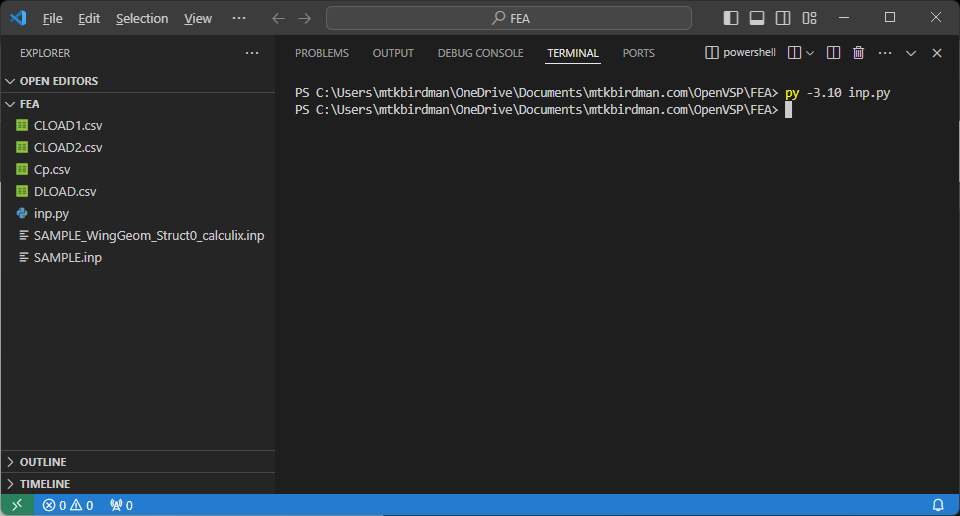
CalculiXをインストールした状態で.inpファイルをダブルクリックすると開くことができる
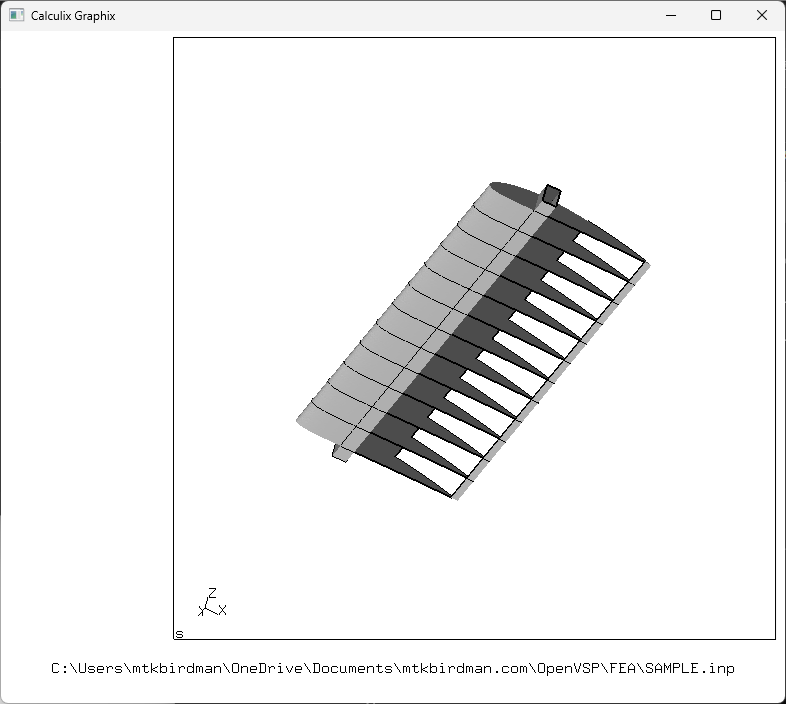
ウィンドウの余白部分を左クリックするとメニューが出てくるので、Datasets>3+dlo 0.000000をクリックする
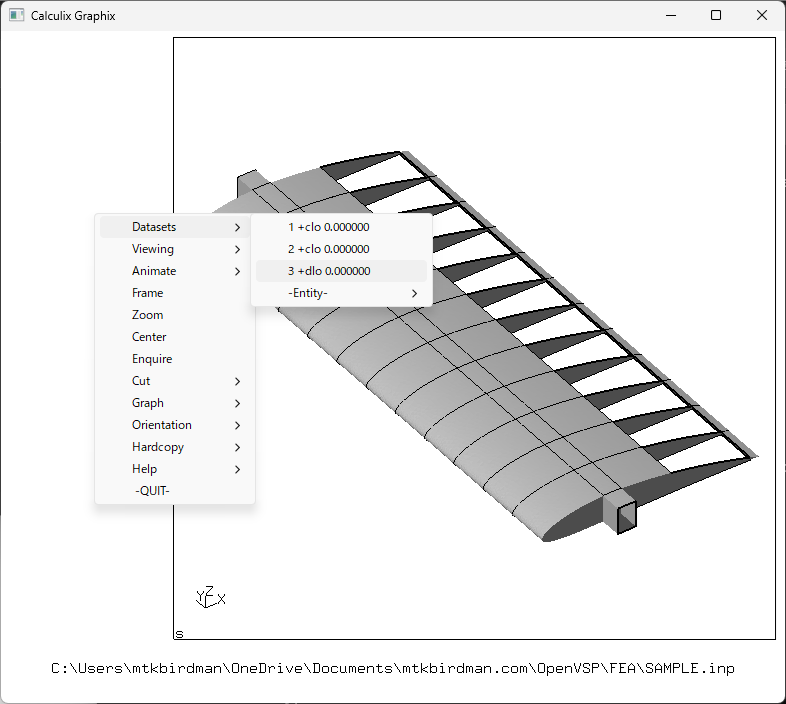
もう一度メニューを出して、Datasets>-Entity->1 val 1をクリックする
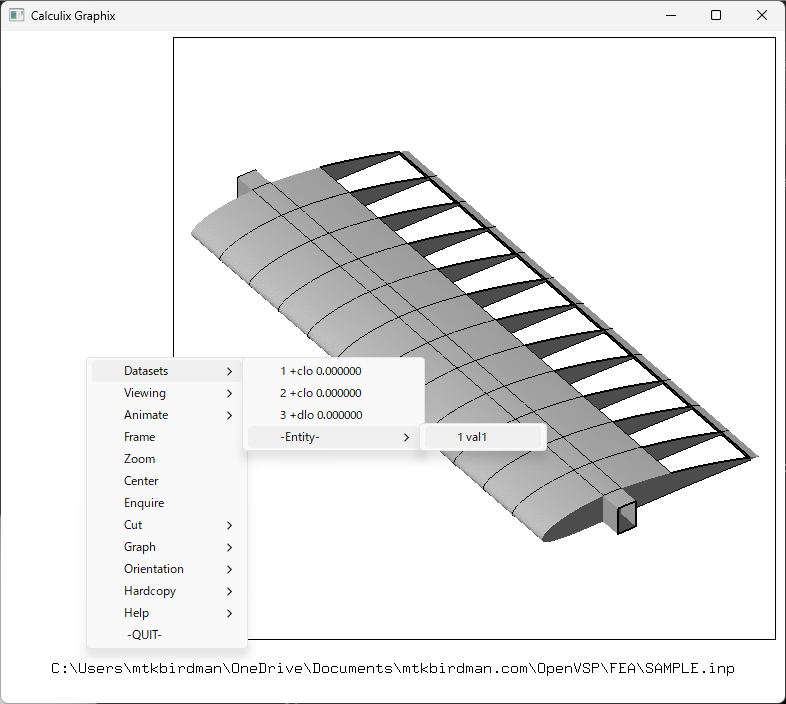
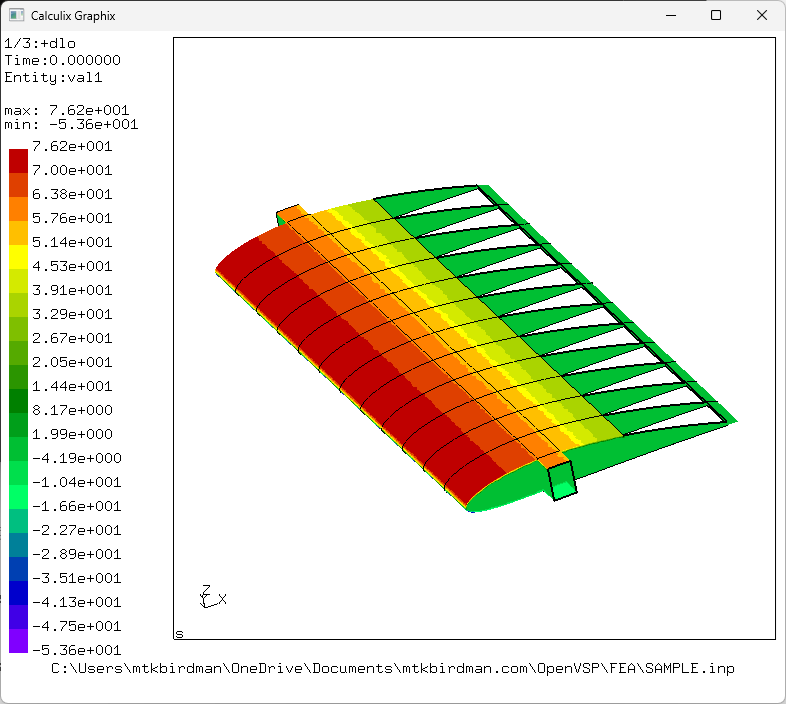
圧力分布が表示される
視点は左クリックでぐるぐる回すことができる
以上
おわりに
CSVファイルの圧力分布をもとにpythonを使ってCalculiXで分布荷重を設定した
ここで作成した.inpファイルを使ってCalculiXでFEMの解析を行う
↓関連記事
コメント